You may be asking me at this point: Why is our application so slow? minutes is a long time to wait to fill some data into a database. Why are we only addressing performance now?
The first answer is that the performance of this data insertion doesn't matter quite so much. We only run it once against the production database.
The "real" answer is because we're awaiting all of the requests in a loop so we only send one at a time. requests across the internet are quite slow, and while the actual queries we're making against PlanetScale can finish in single-digit milliseconds, the request across the internet can not complete quite that fast.
The second answer holds a bit more to it. Async/await and zero-cost futures were first stabilized in late 2019. This has given the ecosystem some time to adopt async Rust such that async runtimes like tokio are now 1.0 and libraries such as sqlx and web frameworks like Rocket have had time to integrate the 1.0 runtimes.
However, this stabilization only included the core framework on which the even higher level async tools are built. Futures are stable, async/await syntax is stable, but Streams are not...
and we're about to use Streams.
This is the point at which I tell you this lesson is optional and you can choose to skip it, just watch it for context, or work through it.
First we need to add a new crate: futures. Yes, the crate has the same name as Futures. This is because futures development was done in this crate before its stabilization. When the Future trait stabilized, some code was moved out of the futures crate into Rust core, and some more code that added extra functionality was left in the futures crate.
cargo add -p upload-pokemon-data futures
The next step is to work with the FuturesUnordered type. This type is something like Promise.all from JavaScript. FuturesUnordered allows us to build up a set of futures that we then wait on all together, allowing them to run in any order (hence why it's called FuturesUnordered).
FuturesUnordered is a collection of futures that can run in any order.
We can create a FuturesUnordered with new.
let tasks = FuturesUnordered::new();
for record in pokemon.clone().into_iter().progress() {
We're then going to change our insert_pokemon call. Instead of awaiting on the result now, we're going to tell tokio "here's a thing we'll want to run later" by using tokio::spawn.
tokio::spawn returns a type called a JoinHandle, which as it happens is also a future. By using spawn we've told tokio to accept the work we want to do and in return tokio has given us a way to tell it when we want to await that work.
Since the return value of tokio::spawn is a Future, we can push that future into tasks which will let us await it alongside all the other tasks later.
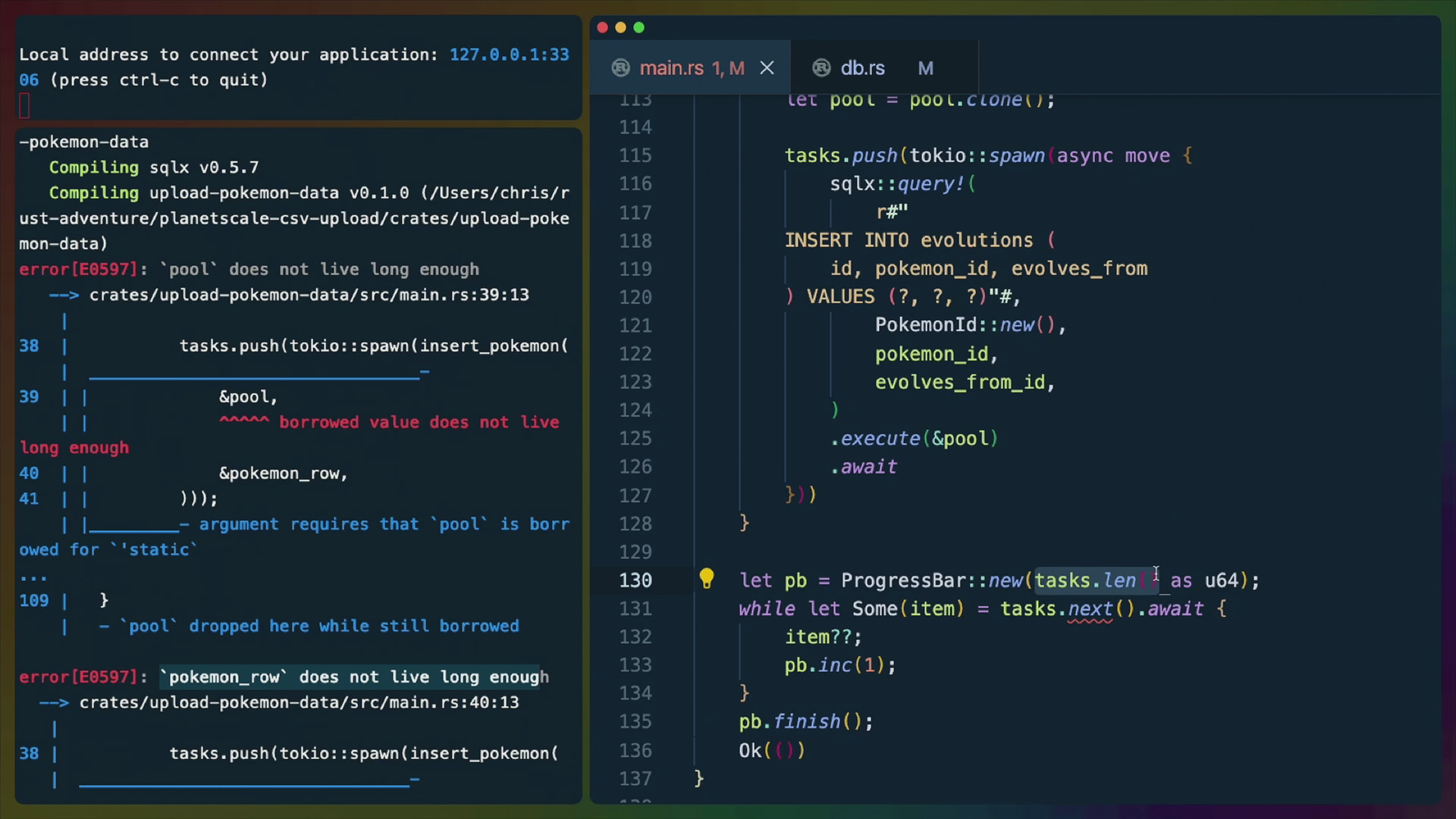
tasks.push(tokio::spawn(insert_pokemon(
&pool,
&pokemon_row,
)));
This code tells us that &pool and &pokemon_row don't live long enough. This is because we can't pass references to spawned async functions. Those references are only going to live for a set amount of time and we've effectively said that we're going to await the future... sometime. There's no guarantee that these references will live that long, so we need to change our insert_pokemon function to not use references.
In src/db.rs remove the & from the arguments
pub async fn insert_pokemon(
pool: MySqlPool,
PokemonTableRow {...}: PokemonTableRow,
)
We also need to change the .execute in that same function to take a reference now.
).execute(&pool).await
Then back in our spawn code, remove the &s as well. We also need to clone the pool, or it will be moved. Luckily if we peek behind the scenes of the Pool type, the authors of sqlx already anticipated this problem and powered the type with an Arc. Arc is an "automatically reference counted" type and is very cheap to clone.
We also clone pokemon_row because we use it in all of the later sql queries, so we are basically giving the task a copy of the pokemon_row it can own and move around however it wants, while we keep ours to use later.
tasks.push(tokio::spawn(insert_pokemon(
pool.clone(),
pokemon_row.clone(),
)));
To do this we need to derive Clone for PokemonTableRow and PokemonId in src/db.rs.
#[derive(Debug, Clone)]
pub struct PokemonTableRow {
#[derive(Clone)]
pub struct PokemonId(Ksuid);
This will clear up the insert_pokemon tasks, but we still have to do the same work for the other tasks.
For abilities we don't have a separate function that can capture the variables we're passing in so that they live as long as the async function, so we need to use an async block.
We've created the local variables (pool, pokemon_id, and ability) and then given them to the Future using the async move syntax. This allows the variables to outlive their original scope but it also means that the local variables can't be used by anything else, which is why we're cloning new copies of them to move into the Future.
The move keyword allows the block to take ownership over the local variables.
for ability in record.abilities.iter() {
let pool = pool.clone();
let pokemon_id = pokemon_row.id.clone();
let ability = ability.clone();
tasks.push(tokio::spawn(async move {
sqlx::query!(
r#"
INSERT INTO abilities (
id, pokemon_id, ability
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_id,
ability,
)
.execute(&pool)
.await
}));
}
Rinse, repeat for the other two sql query loops
for egg_group in record.egg_groups.iter() {
let pool = pool.clone();
let pokemon_id = pokemon_row.id.clone();
let egg_group = egg_group.clone();
tasks.push(tokio::spawn(async move {
sqlx::query!(
r#"
INSERT INTO egg_groups (
id, pokemon_id, egg_group
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_id,
egg_group,
)
.execute(&pool)
.await
}))
}
for typing in record.typing.iter() {
let pool = pool.clone();
let pokemon_id = pokemon_row.id.clone();
let typing = typing.clone();
tasks.push(tokio::spawn(async move {
sqlx::query!(
r#"
INSERT INTO typing (
id, pokemon_id, typing
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_id,
typing,
)
.execute(&pool)
.await
}))
}
and again for the evolutions queries. Every time we're repeating the same concepts. prep the variables, move the new variables into an async block, add the spawned future to tasks for later.
for pokemon in pokemon
.into_iter()
.progress()
.filter(|pokemon| pokemon.evolves_from.is_some())
{
let name = pokemon.evolves_from.expect(
"Expected a value here since we just checked",
);
let pokemon_id =
pokemon_map.get(&pokemon.name).unwrap().clone();
let evolves_from_id =
pokemon_map.get(&name).unwrap().clone();
let pool = pool.clone();
tasks.push(tokio::spawn(async move {
sqlx::query!(
r#"
INSERT INTO evolutions (
id, pokemon_id, evolves_from
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_id,
evolves_from_id,
)
.execute(&pool)
.await
}))
}
Now that we have all of our futures set up in a FuturesUnordered, we can await the Stream.
To be able to call .next() on the tasks, tasks needs to be mutable, so head back up and add mut to the tasks declaration.
let mut tasks = FuturesUnordered::new();
We're going to create our own ProgressBar instead of ataching to an iterator this time.
We have to use while let syntax to operate on the Stream. A for loop will not work here. One day we might have something like async for but we do not today.
While tasks.next().await still produces Some(item), where tasks.next() is an async function that gives us the result of whatever future finishes next. So when we await on tasks.next() we either get Some(item) which means there are still items left in the stream, or None which means the stream is done.
item then, is the result of the JoinHandle future.
In this case, that means we have nested Results, one for the JoinHandle and one for our own return value.
Result<Result<MySqlQueryResult, Error>, JoinError>
ProgressBar already has it's own Arc, so we don't need to worry about it and can .inc(1) to tick the progress bar once for each completed task.
Finally we .finish the progress bar when we're done processing.
let pb = ProgressBar::new(tasks.len() as u64);
while let Some(item) = tasks.next().await {
item??;
pb.inc(1);
}
pb.finish();
We run into an error fairly quickly though
pool timed out while waiting for an open connection
We're now in debugging territory. Good ideas might be to search the sqlx github issues, or the discord history. Either way we'd end up finding our that when using a large amount of futures like we are now, we either need to increase the timeout or make it so that the futures complete faster so that enough mysql connections are freed up and returned to the pool so that all the futures can complete in the timeout time.
Our max_connections for the pool is 5 right now which is kinda low for us. We could crank that up to 50 and PlanetScale wouldn't really care. Contrary to some other SQL providers, connections are cheap for PlanetScale. This is one of the reasons we can use it from serverless functions.
The default connection timeout is 30 seconds though, so we either need to complete our script in 30 seconds or we get the boot.
We'll need std::time::Duration.
use std::{collections::HashMap, env, time::Duration};
Since we're not using sqlx in a server context right now, we kinda just want it to wait on a connection for awhile. No user is waiting for a request to complete.
With 50 max connections and 5 minutes (5 * 60 seconds), our pool initialization looks like this now.
let pool = MySqlPoolOptions::new()
.max_connections(50)
.connect_timeout(Duration::from_secs(60 * 5))
.connect(&database_url)
.await
.suggestion("database urls must be in the form `mysql://username:password@host:port/database`")?;
With these new settings and the added concurrency of FuturesUnordered, it took me just under 60 seconds to complete all ~7000 requests to PlanetScale.