OK, so we have all of the pokemon in the pokemon table now. We need to go back and fill in a few more tables using the same techniques to cover the fields we left out when we created the pokemon table.
These extra tables are
- abilities
- typings
- egg_groups
- evolves_from
The SQL for these tables goes at the bottom of creates.sql. It follows the same structure as the original pokemon table, so if you don't recognize any of the syntax or types here refer back to that lesson for the explanations.
While other approaches to databases might have us store all of a pokemon's data in one record, SQL likes it a lot if we split the data up across a bunch of different tables. This way the SQL language lets us join across all of those tables and their relationships.
To allow joining tables together when querying, we have to have a field to join on. pokemon_id, the id field from our pokemon table, is a great choice as we'll often be joining to our core pokemon table. Each of our additional tables then will have their own ids for each row (id), the pokemon_id for the pokemon they're related to, and the special field they represent.
CREATE TABLE IF NOT EXISTS abilities(
id VARBINARY(27) NOT NULL, -- ksuid
pokemon_id VARBINARY(27) NOT NULL,
ability VARCHAR(16) NOT NULL,
PRIMARY KEY ( id )
);
CREATE TABLE IF NOT EXISTS typing(
id VARBINARY(27) NOT NULL, -- ksuid
pokemon_id VARBINARY(27) NOT NULL,
typing VARCHAR(8) NOT NULL,
PRIMARY KEY ( id )
);
CREATE TABLE IF NOT EXISTS egg_groups(
id VARBINARY(27) NOT NULL, -- ksuid
pokemon_id VARBINARY(27) NOT NULL,
egg_group VARCHAR(13) NOT NULL,
PRIMARY KEY ( id )
);
CREATE TABLE IF NOT EXISTS evolutions(
id VARBINARY(27) NOT NULL, -- ksuid
pokemon_id VARBINARY(27) NOT NULL,
evolves_from VARBINARY(27) NOT NULL,
PRIMARY KEY ( id )
);
The only odd table out is evolutions, which instead of storing a string/varchar, stores an additional pokemon id in evolves_from.
So in the end we have 5 tables. We can run the script now to create the additional four.
pscale shell pokemon new-tables
pokemon/new-tables> source crates/upload-pokemon-data/create-tables.sql
With the tables created, it's time to write the rust to insert the additional data.
Right below insert_pokemon we can add what are essentially three copies of the same code with slight alterations.
for record in pokemon.into_iter().progress() {
let pokemon_row: PokemonTableRow = record.into();
insert_pokemon(&pool, &pokemon_row).await?;
for ability in record.abilities.iter() {
sqlx::query!(
r#"
INSERT INTO abilities (
id, pokemon_id, ability
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_row.id,
ability,
)
.execute(&pool)
.await?;
}
for egg_group in record.egg_groups.iter() {
sqlx::query!(
r#"
INSERT INTO egg_groups (
id, pokemon_id, egg_group
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_row.id,
egg_group,
)
.execute(&pool)
.await?;
}
for typing in record.typing.iter() {
sqlx::query!(
r#"
INSERT INTO typing (
id, pokemon_id, typing
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_row.id,
typing,
)
.execute(&pool)
.await?;
}
}
First we iterate over the abilities in the PokemonCsv. For each ability, we run a SQL query that looks very similar in structure to our pokemon "insert into" query. We generate a new PokemonId for the row key, pass the id we generated for the pokemon row in as the second argument, and finally the ability string. Then we execute, await, and ? just like before.
Rinse, repeat two more times.
for ability in record.abilities.iter() {
sqlx::query!(
r#"
INSERT INTO abilities (
id, pokemon_id, ability
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_row.id,
ability,
)
.execute(&pool)
.await?;
}
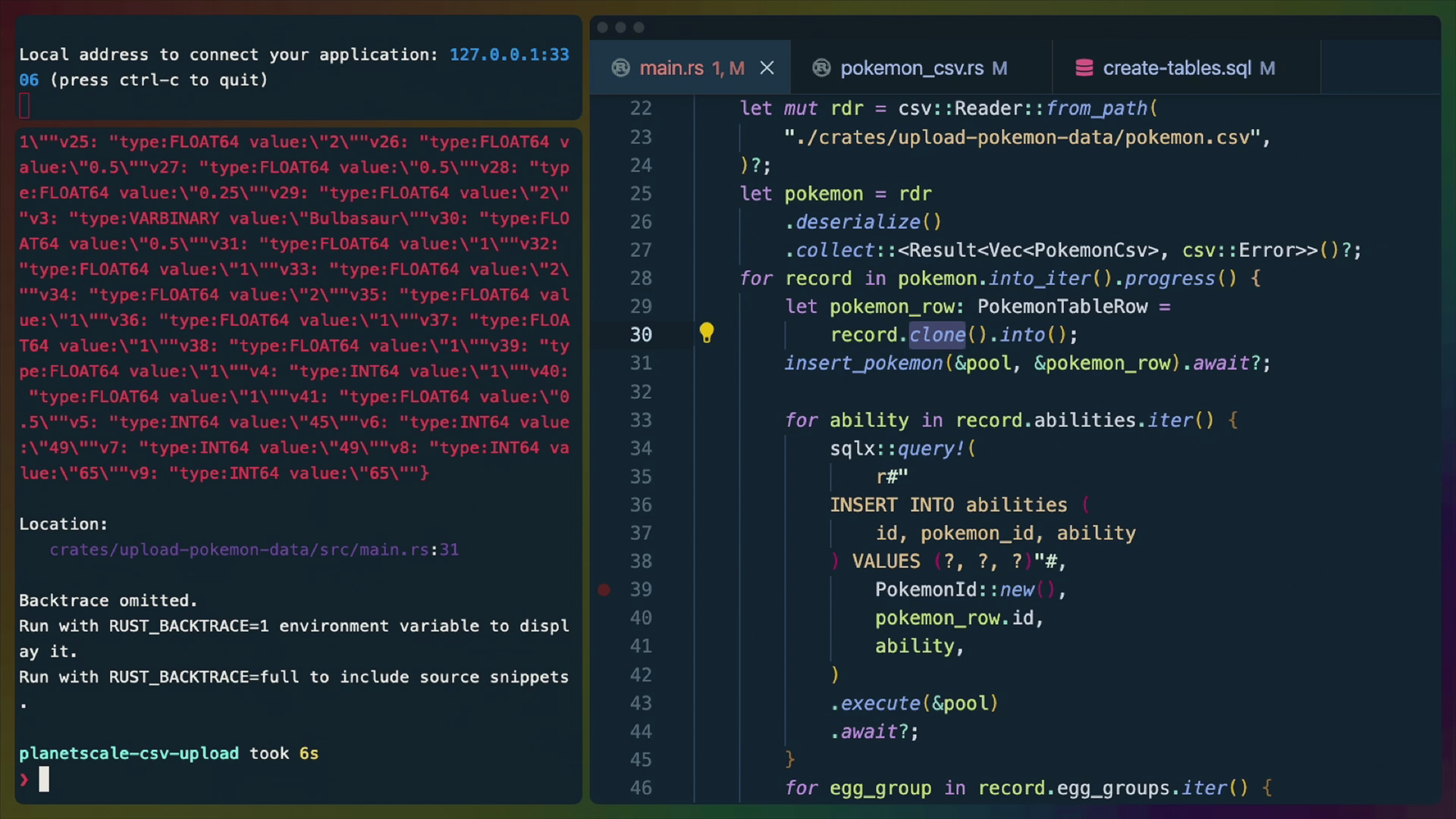
With this code, we do run into one problem.
error[E0382]: borrow of moved value: `record`
--> crates/upload-pokemon-data/src/main.rs:60:23
|
31 | for record in pokemon.into_iter().progress() {
| ------ move occurs because `record` has type `pokemon_csv::PokemonCsv`, which does not implement the `Copy` trait
32 | let pokemon_row: PokemonTableRow = record.into();
| ------ `record` moved due to this method call
...
60 | for typing in record.typing.iter() {
| ^^^^^^^^^^^^^^^^^^^^ value borrowed here after move
PokemonCsv doesn't implement Copy and Rust's semantics are move by default, so when we use it to make the PokemonTableRow with into, it gets moved and we no longer have access to it.
If we try to clone the record before we into, we get another error
error[E0599]: no method named `clone` found for struct `pokemon_csv::PokemonCsv` in the current scope
--> crates/upload-pokemon-data/src/main.rs:33:20
|
33 | record.clone().into();
| ^^^^^ method not found in `pokemon_csv::PokemonCsv`
|
::: crates/upload-pokemon-data/src/pokemon_csv.rs:4:1
|
4 | pub struct PokemonCsv {
| --------------------- method `clone` not found for this
|
and yeah, we haven't implemented Copy OR Clone for PokemonCsv.
In this case, we don't much care about needing to clone a few times, so we'll derive Clone for PokemonCsv in src/pokemon_csv.
#[derive(Debug, Deserialize, Clone)]
pub struct PokemonCsv {
and now our clone in src/main.rs works.
let pokemon_row: PokemonTableRow = record.clone().into();
That covers three of our four tables.
The last data we have to insert is the evolutions table. This will require us to get two pokemon ids, which means we need a way to look up the ids.
evolves_from in the csv is a pokemon's name, so we'll have to match on that to find the ids.
Above our for loop, we can create a new HashMap. HashMaps are a bit like JavaScript objects, we can stick whatever we want in as long as the types match, and get that data out later by key.
Bring std::collections::HashMap into scope. It's part of the standard library, so it can share a use with std::env. I like this approach because it shows us everything we're using from a given crate (or the standard library) in one place.
use std::{collections::HashMap, env};
We'll use the pokemon name as our keys, which will be a String, and the id of that pokemon as our values. We've chosen to make a mutable HashMap and insert values into it rather than using some version of .collect.
At the bottom of the for loop, we'll insert new keys and values for each pokemon we're iterating over.
let mut pokemon_map: HashMap<
String,
PokemonId,
> = HashMap::new();
for record in pokemon.into_iter().progress() {
...
pokemon_map.insert(record.name, pokemon_row.id);
}
After our first for loop, we can build up another for loop over the pokemon Vec. We'll use into_iter to grab ownership of the PokemonCsvs. Note that this will require us to .clone() the original pokemon usage like this:
for record in pokemon.clone().into_iter().progress() {
After we get an iterator from pokemon, we attach a progress bar just like before. We do this before the filter because we don't actually know how many items the filter will remove, so we lose the ExactSizeIterator implementation after applying the filter.
The filter checks to see if evolves_from on a given pokemon has a value. Option types are either Some(value) or None and we only want to operate on pokemon that evolve from another pokemon, which we can decide with is_some, a function on the Option type.
for pokemon in pokemon
.into_iter()
.progress()
.filter(|pokemon| pokemon.evolves_from.is_some())
{
let name = pokemon.evolves_from.expect(
"Expected a value here since we just checked",
);
let pokemon_id = pokemon_map.get(&pokemon.name);
let evolves_from_id = pokemon_map.get(&name);
sqlx::query!(
r#"
INSERT INTO evolutions (
id, pokemon_id, evolves_from
) VALUES (?, ?, ?)"#,
PokemonId::new(),
pokemon_id,
evolves_from_id,
)
.execute(&pool)
.await?;
}
Because we've just filtered for only pokemon that have an evolves_from value, we can .expect to unwrap the Option and get the name of the pokemon the current pokemon evolves from.
Then we can use the name of the current pokemon and the name we got from the evolves_from field to grab the ids of both relevant pokemon from the HashMap we constructed earlier.
The sql query looks very similar to all of the other sql queries we've gone over in this lesson, with different table names and column names.
Now we've got a SQL script to create our tables and a program to insert our data.
The full flow looks like this to create the tables (remember to drop table pokemon if you want to insert everything from scratch).
❯ pscale shell pokemon new-tables
pokemon/new-tables> source crates/upload-pokemon-data/create-tables.sql
and then pscale connect to initiate a database connection
pscale connect express-node-test new-tables
and cargo run to execute our program.
DATABASE_URL=mysql://127.0.0.1 cargo run
This program will take some minutes to run as we've 4x'd the amount of requests we make and then wait to complete.
The next (optional) lesson will be about performance.