Database types are not your application types
While the PokemonCsv type accurately reflects the data we're pulling out of the csv rows, it doesn't necessarily represent the data as it will exist in our database.
The reason for this is readily apparent in two places in our data. One is that we don't have a unique id in our csv. Even the pokedex_id, which should uniquely identify each pokemon, is re-used in this dataset to represent different variations (Gigamax and Mega) of different pokemon.
Here's a nushell script that proves this is true for our dataset.
❯ open ./crates/upload-pokemon-data/pokemon.csv | select name pokedex_id | where name =~ "Charizard"
───┬──────────────────┬────────────
# │ name │ pokedex_id
───┼──────────────────┼────────────
0 │ Charizard │ 6
1 │ Charizard Gmax │ 6
2 │ Charizard Mega X │ 6
3 │ Charizard Mega Y │ 6
───┴──────────────────┴────────────
Secondly, when we build an api from this data we're going to want to access a pokemon by name. A user of the API will know their favorite pokemon (perhaps "Bulbasaur") but not the pokedex_id, and definitely not whatever id we use in the database.
The best way then to use a name in a URL is to slugify it. Charizard Mega X would become charizard-mega-x.
These two fields: a database id and a slugified name are additional fields that will live in our database that don't live in the csv.
There are other, more subtle changes to make as well. In PokemonCsv we use a u8 for a few numbers. This works fine for the u8, but we actually have no idea what future pokemon will have for these values. height and weight already need to fit in a u16 but when will hp, which already has two pokemon at the max u8 value (255).
We aren't trying to squeeze into as small of a footprint as possible, so using u16 instead of u8 like the PokemonCsv type does will let us be more forward-compatible.
In src/main.rs we'll add a new sub-module called db and bring all of its public items into scope. This is exactly the same thing we did for pokemon_csv.rs.
mod db;
mod pokemon_csv;
use db::*;
use pokemon_csv::*;
In a new file called db.rs we'll define our new Pokemon type to represent a row in our database table.
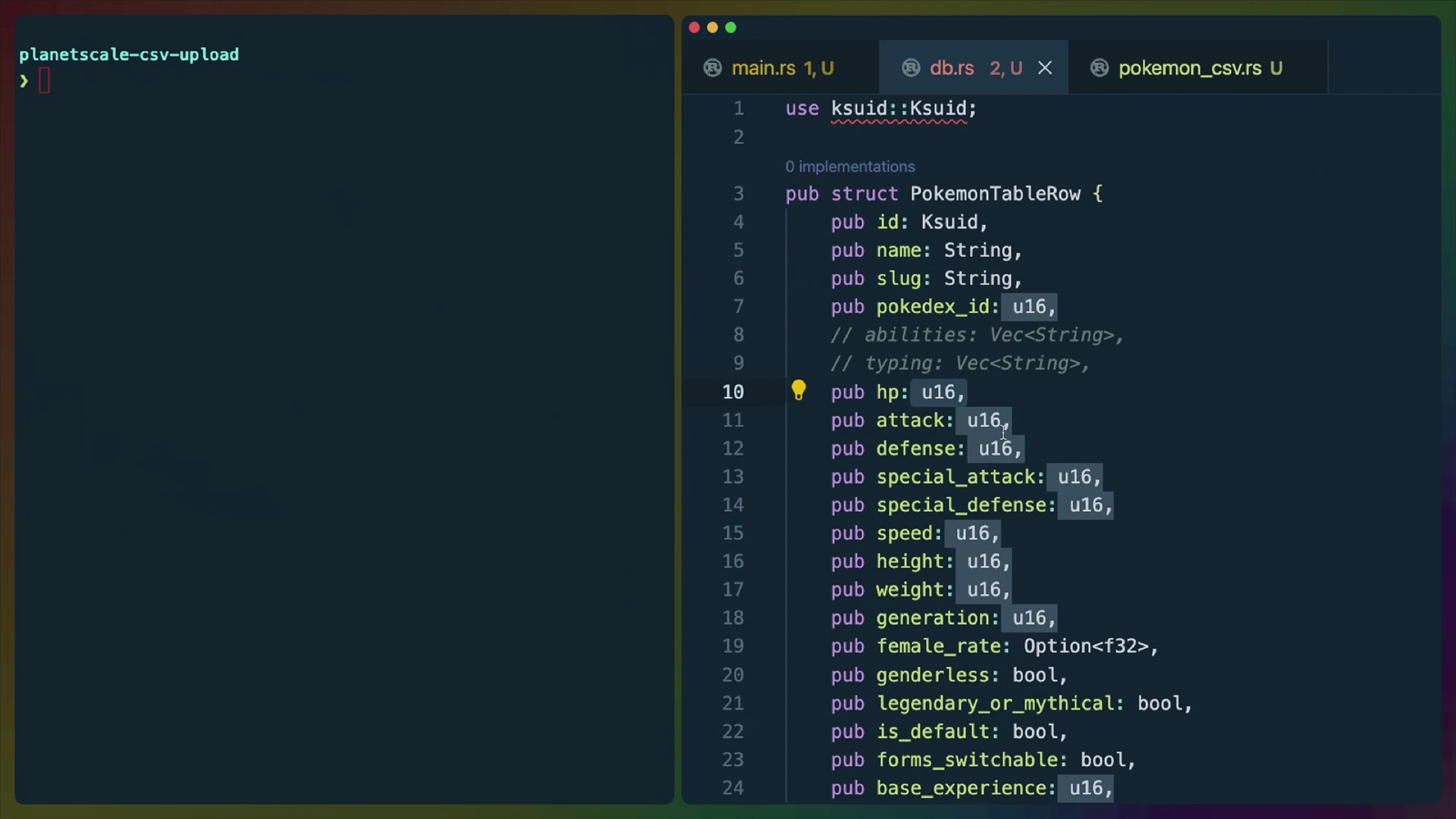
The new PokemonTableRow type looks like this.
use ksuid::Ksuid;
pub struct PokemonTableRow {
pub id: Ksuid,
pub name: String,
pub slug: String,
pub pokedex_id: u16,
// abilities: Vec<String>,
// typing: Vec<String>,
pub hp: u16,
pub attack: u16,
pub defense: u16,
pub special_attack: u16,
pub special_defense: u16,
pub speed: u16,
pub height: u16,
pub weight: u16,
pub generation: u16,
pub female_rate: Option<f32>,
pub genderless: bool,
pub legendary_or_mythical: bool,
pub is_default: bool,
pub forms_switchable: bool,
pub base_experience: u16,
pub capture_rate: u16,
// egg_groups: Vec<String>,
pub base_happiness: u16,
// evolves_from: Option<String>,
pub primary_color: String,
pub number_pokemon_with_typing: f32,
pub normal_attack_effectiveness: f32,
pub fire_attack_effectiveness: f32,
pub water_attack_effectiveness: f32,
pub electric_attack_effectiveness: f32,
pub grass_attack_effectiveness: f32,
pub ice_attack_effectiveness: f32,
pub fighting_attack_effectiveness: f32,
pub poison_attack_effectiveness: f32,
pub ground_attack_effectiveness: f32,
pub fly_attack_effectiveness: f32,
pub psychic_attack_effectiveness: f32,
pub bug_attack_effectiveness: f32,
pub rock_attack_effectiveness: f32,
pub ghost_attack_effectiveness: f32,
pub dragon_attack_effectiveness: f32,
pub dark_attack_effectiveness: f32,
pub steel_attack_effectiveness: f32,
pub fairy_attack_effectiveness: f32,
}
There are two more pieces of this code to mention. First is that we've commented out all of the fields that are Vec types. This is because MySql, and thus PlanetScale, doesn't support arrays of values. Instead we'll model each of these arrays as a row in a different table and if we want to return them in results, we'll have to join on those tables.
The second is that we've given our id a type of Ksuid which is a crate we haven't installed yet.
cargo add -p upload-pokemon-data ksuid
As we said before, we don't have an id in our csv for each pokemon row. Therefore we must create one. While there are many approaches to this, the one I've chosen for this project is to use a ksuid.
While this isn't super important for our use case here, some of the most common alternatives have some drawbacks we want to avoid in future database work.
auto-incrementing numeric ids, that is a sequence like 1,2,3,4,5,etc, can leak data unintentionally. If you use an auto-incrementing id for say, user accounts, someone can tell how many users are signed up by looking at their id and even track this across time by making a user account each week. This also makes guessing the id for someone else's resources easier. Their first project will be project 1, then 2, and so on.
Additionally, since we're using PlanetScale which runs on Vitess, an implementation of a sharded MySQL, auto-increment ids will cause us to end up with duplicate ids across different shards. (Ask two people to both count up from 0 by 1 and you'll see the problem).
UUIDs are another type of id we could use, but in the most common version of UUID, these aren't sortable, they're random! Consider the case of storing something like tweets. It's very useful to be able to sort by the creation time. Ksuids sort this way naturally, while UUIDs will return a random ordering of tweets.
So in the end, while it's not critical to our current use case, we did have to pick an id type and why not pick a good one we can use in many other projects.
A ksuid in string form looks like this: 1xTyKhMmBYTsQRWx4bpEOQTGJQ2.